Everything Everywhere All at Once: How Transformers Changed the Way Machines Understand Language
In 2017, Google researchers proposed throwing out sequential language processing entirely. Their Transformer architecture could see everything, everywhere, all at once—and it changed AI forever.
An Ever-Present Reservoir of Infinite Possibilities
In 2022, a delightfully strange film swept the Academy Awards. Everything Everywhere All at Once depicted a woman simultaneously experiencing infinite parallel realities, processing them all at the same moment to save the universe. It's a beautiful metaphor for something that happened five years earlier in a Google research lab—something that would eventually reshape how we think about artificial intelligence.
That something was the Transformer.
The Old Way: One Word at a Time
To understand why Transformers matter, you need to understand what came before them.
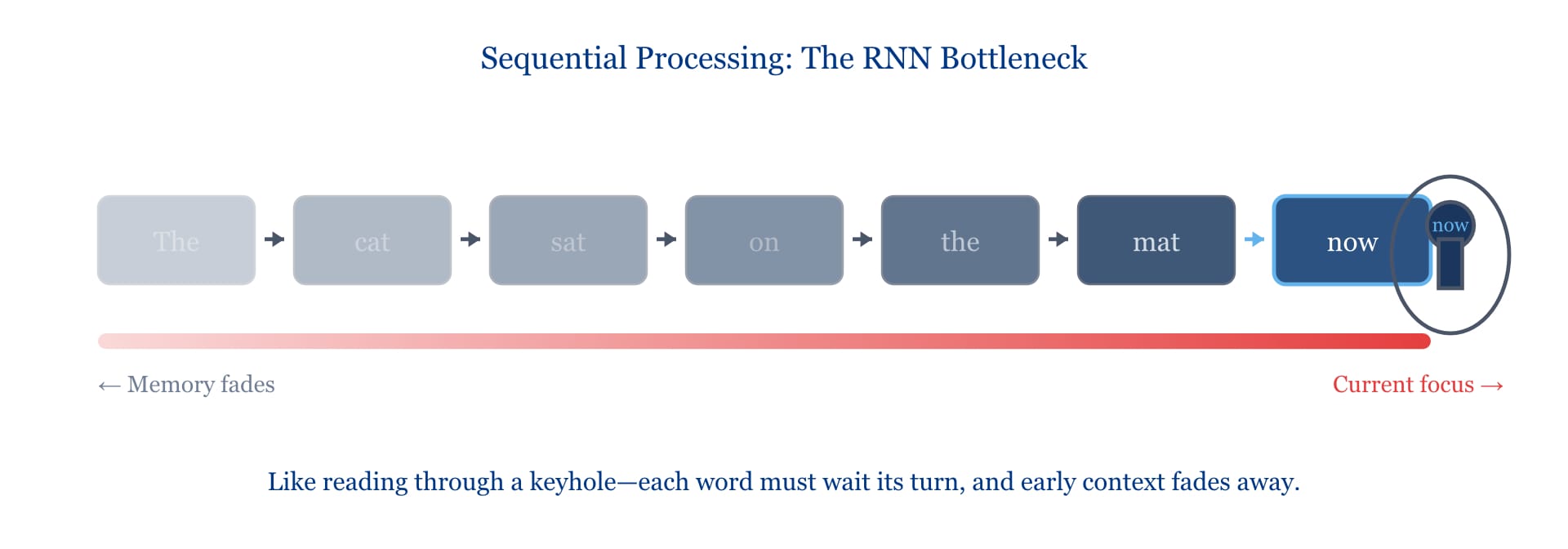
Imagine reading a novel through a keyhole. You can only see one word at a time, and you must remember everything you've read while trying to make sense of what comes next. This was essentially how neural networks processed language before 2017.
These earlier systems—called Recurrent Neural Networks, or RNNs—read text sequentially, one token after another, like a person sounding out words on a page. Each word had to wait its turn. The network maintained a kind of running memory, updating its understanding as each new word arrived.
The RNN Bottleneck
The problem? Memory fades. By the time an RNN reached the end of a long sentence, it had often forgotten the beginning. Researchers tried various remedies—Long Short-Term Memory networks (LSTMs) added more sophisticated memory cells, like Post-it notes the network could choose to keep or discard. These helped, but the fundamental bottleneck remained: processing happened one step at a time.
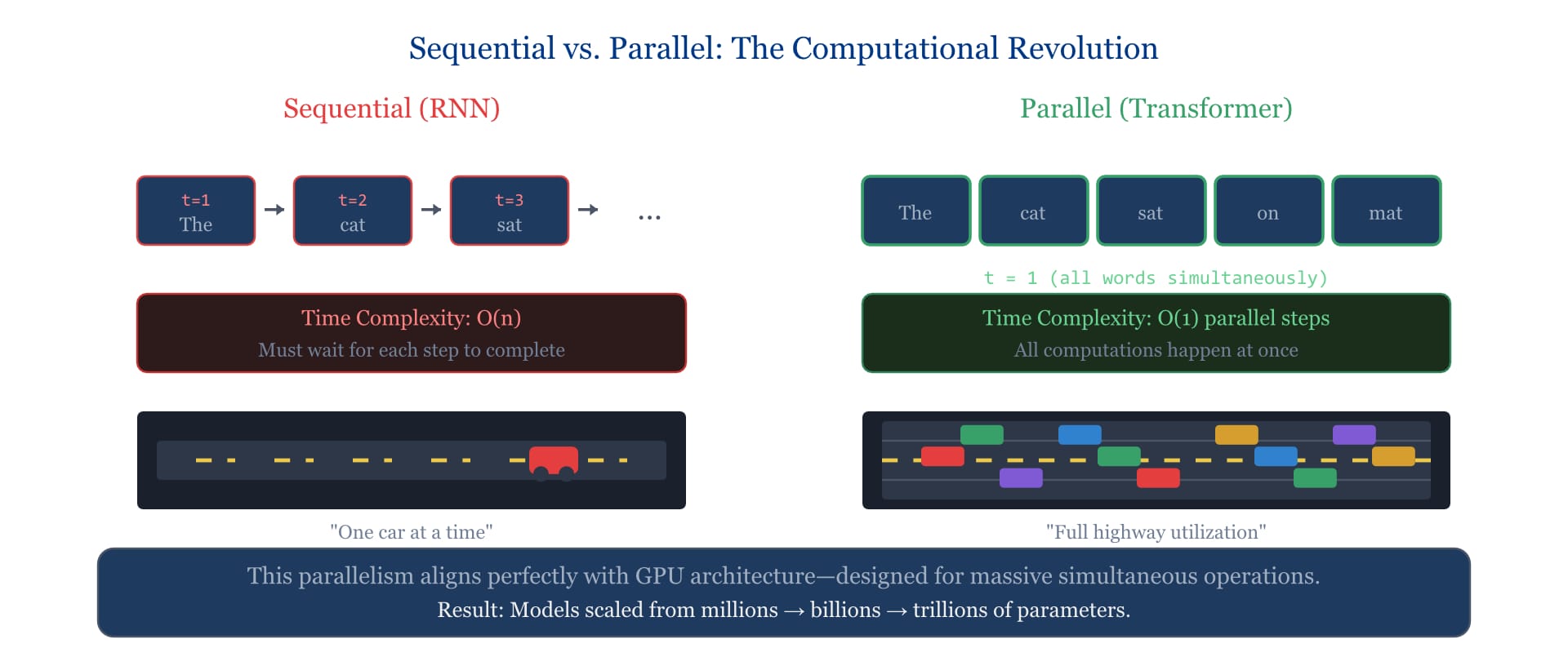
There was another problem, too. Sequential processing is slow. You can't start reading word fifty until you've finished words one through forty-nine. In an era of massive datasets and parallel computing hardware, this was like owning a highway but only allowing one car on it at a time.
The Eureka Moment: Attention Is All You Need
In June 2017, a team of researchers at Google published a paper with a title that bordered on audacious: "Attention Is All You Need."
The authors—Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez, Łukasz Kaiser, and Illia Polosukhin—proposed throwing out the sequential approach entirely. Their new architecture, which they called the Transformer, could process an entire sequence simultaneously.
Everything, everywhere, all at once.
The Cocktail Party Explanation
Here's an intuition for how attention works.
You're at a crowded party. Dozens of conversations swirl around you—laughter here, an argument there, someone telling a story about their vacation. Your brain doesn't process all of this sequentially. Instead, you unconsciously attend to what matters. When someone across the room says your name, you snap to attention. When a topic you care about comes up, you tune in.
This is selective attention, and it's remarkably efficient. You're processing the entire room simultaneously, but directing your cognitive resources toward what's relevant.
Transformers do something similar. When processing a sentence, every word can "look at" every other word simultaneously. But here's the key insight: not all words matter equally to each other.
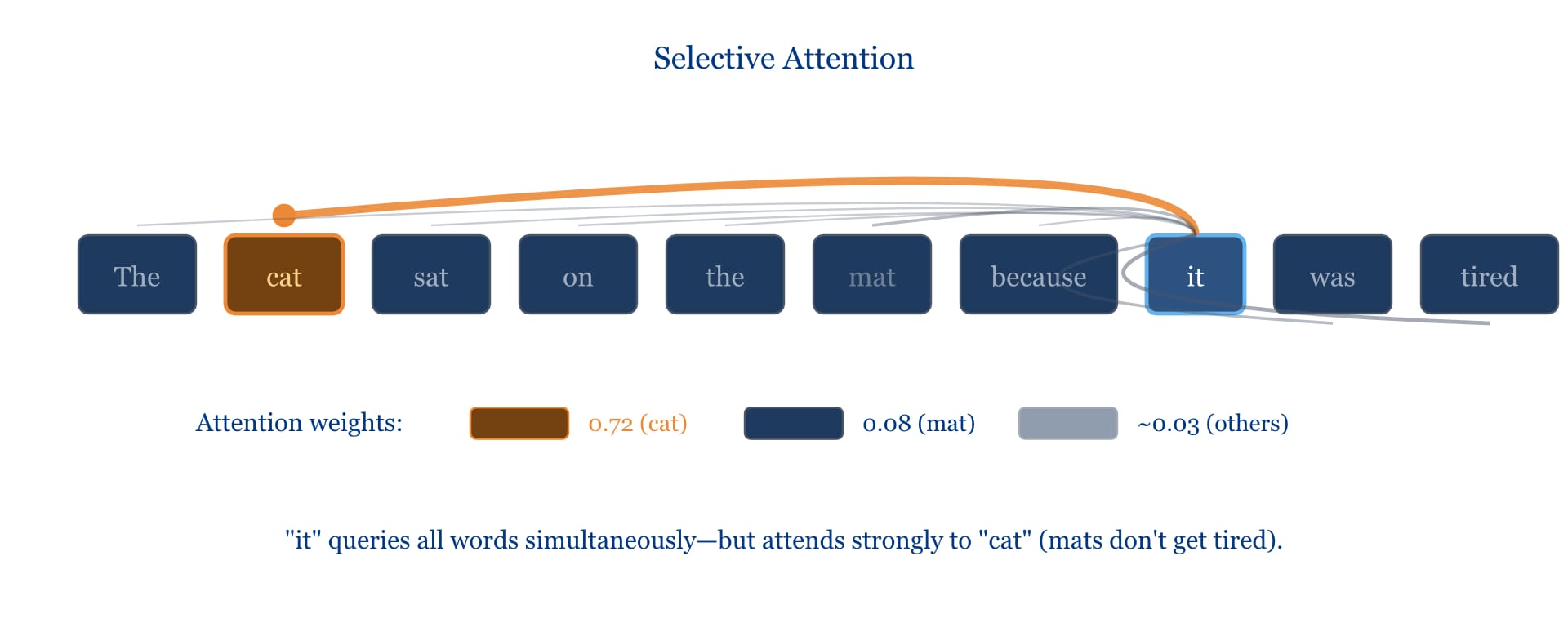
Consider: "The cat sat on the mat because it was tired."
What does "it" refer to? Almost certainly the cat, not the mat. Mats don't get tired. A Transformer learns to make this connection by having the word "it" attend strongly to "cat" and weakly to "mat." It's measuring relevance—which parts of the sentence matter most for understanding each part.
Three Questions Every Word Asks
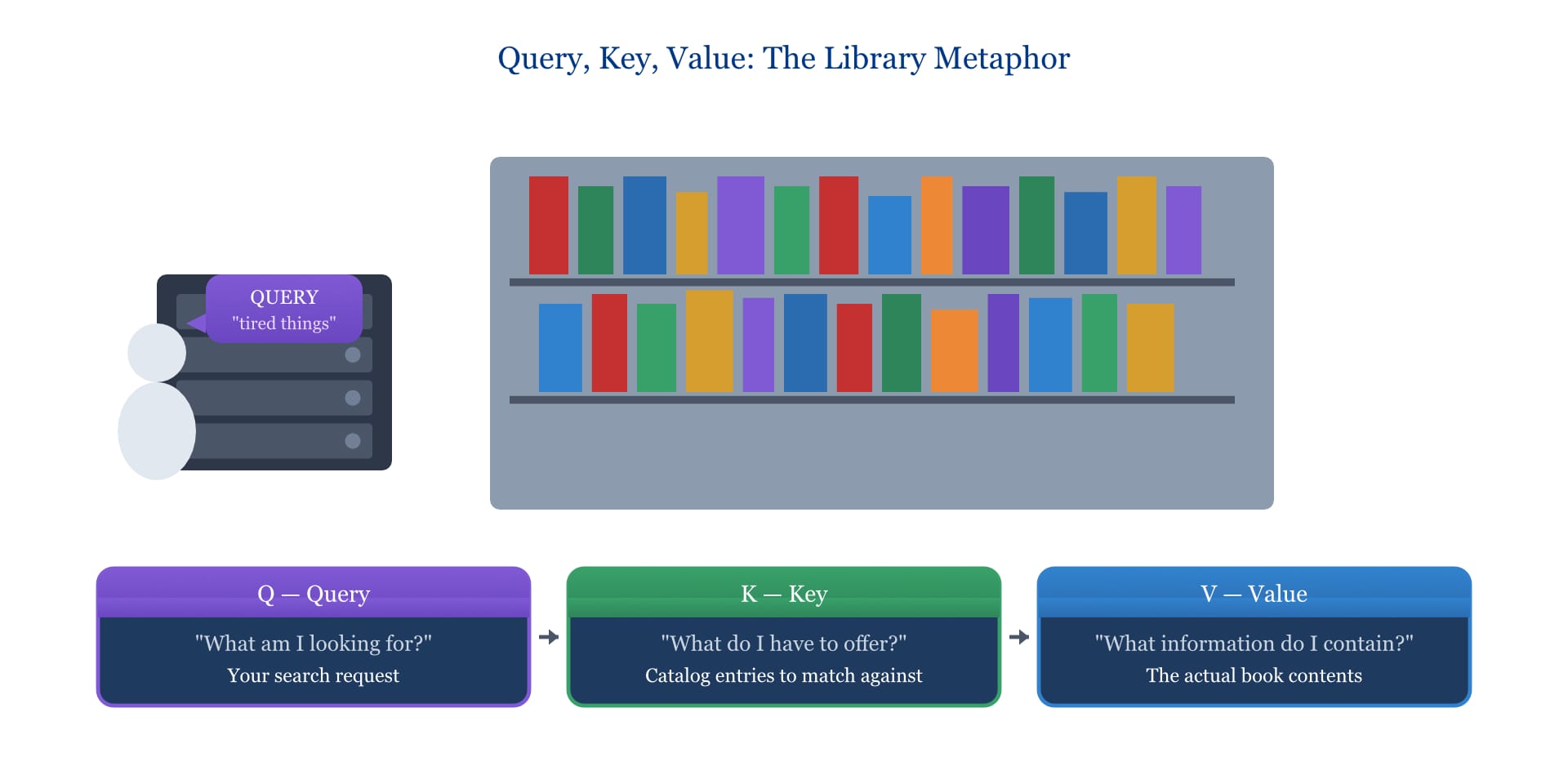
The mechanics of attention rest on a simple framework. For every word in a sequence, the Transformer computes three things:
Query: "What am I looking for?" Key: "What do I have to offer?" Value: "What information do I contain?"
Think of it like a library. When you search for information (your query), you compare it against the catalog entries (keys) to find matches. When you find a match, you retrieve the actual book contents (values).
Three Questions Every Word Asks: Query + Key + Value
Every word broadcasts its key to all other words. Every word also sends out a query. The attention mechanism compares each query against all keys, computing a relevance score. Words with high relevance scores contribute more of their value to the final understanding.
This happens in parallel—all words querying all other words simultaneously. No waiting in line. No fading memories.
The Magic of Self-Attention
What makes this "self-attention" rather than just "attention" is that words attend to each other within the same sequence. The sentence is having a conversation with itself.
Meaning Emerges from Relationships
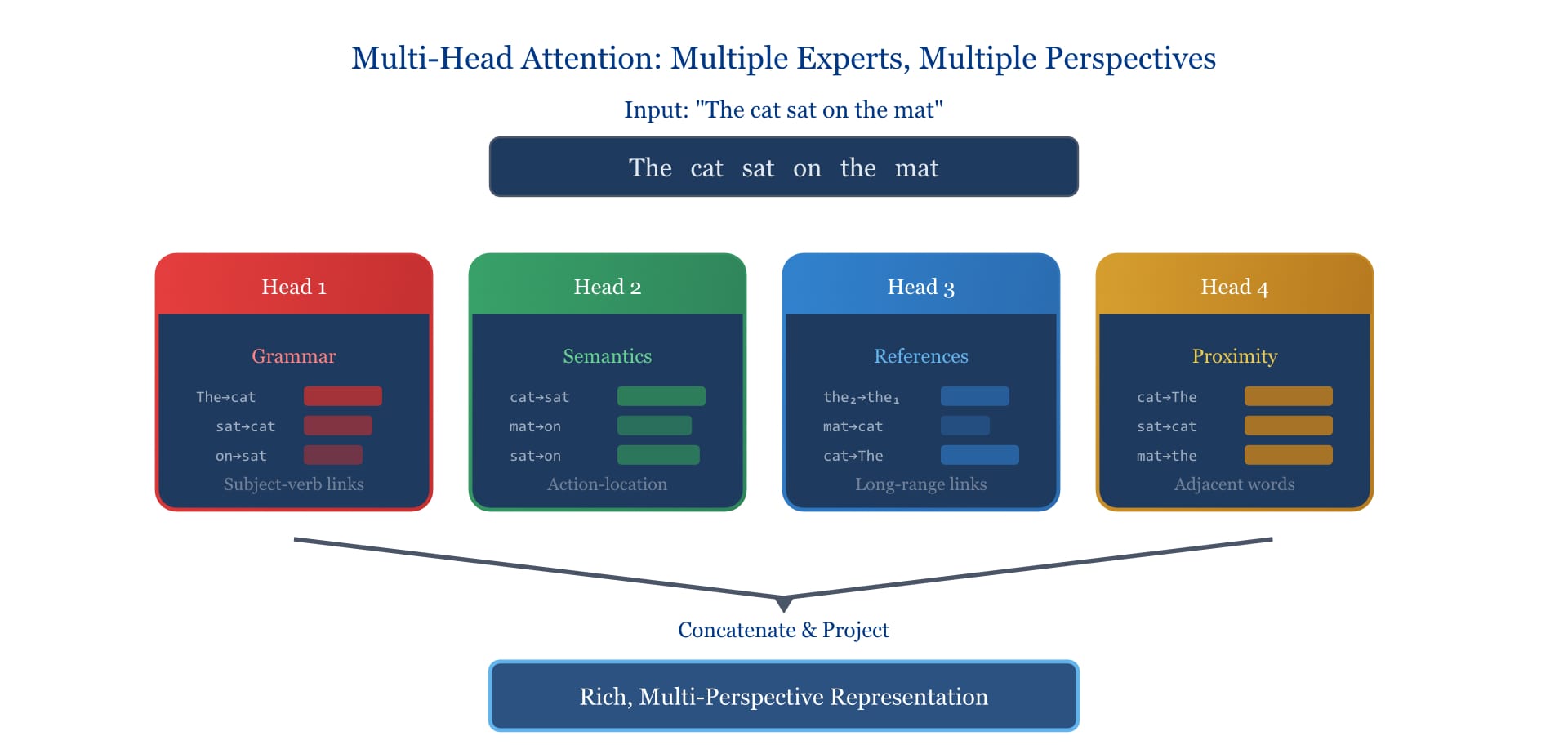
This captures something profound about language. Meaning isn't found in isolated words—it emerges from relationships. The word "bank" means something different in "river bank" versus "investment bank." Self-attention allows the model to see both contexts simultaneously and adjust accordingly.
Moreover, Transformers use multiple "attention heads"—parallel attention mechanisms, each learning to focus on different types of relationships. One head might specialize in grammatical structure, another in semantic meaning, another in tracking references across long distances. It's like having multiple experts read the same text, each bringing their own lens.
A Historical Echo: Shannon and Information Theory
There's a lovely historical resonance here. In 1948, Claude Shannon published "A Mathematical Theory of Communication," founding the field of information theory. Shannon showed that the information content of a message depends on context—on what's probable given what came before.
Claude Shannon - The Father of Information Theory
Shannon built simple language models himself. Given a sequence of letters, his models predicted what letter might come next based on frequency statistics. These were crude compared to modern systems, but the principle endures: language understanding is fundamentally about relationships and context.
Transformers are Shannon's insight taken to its logical extreme. Rather than just looking at what came immediately before, they consider everything simultaneously—every relationship, every potential context, every relevant connection.
Why "All at Once" Matters
The parallelism of Transformers isn't just an engineering convenience. It's a conceptual revolution.
Sequential processing forces a particular interpretation of time and causality. Word A comes before word B, which comes before word C. The architecture itself embeds this assumption.
Parallel processing liberates the model. Now the end of a sentence can inform the beginning as much as the beginning informs the end. Long-range dependencies—"the man who saw the woman who carried the dog that bit the mailman was my neighbor"—become tractable. The model sees the whole structure at once.
Sequential vs. Parallel Computation
This is also why Transformers scale so well. Modern GPU hardware is designed for massive parallelism—performing the same operation on thousands of data points simultaneously. Sequential models couldn't exploit this. Transformers can. This alignment between architecture and hardware is what enabled the explosion from millions to billions to trillions of parameters.
Position Matters (But Differently)
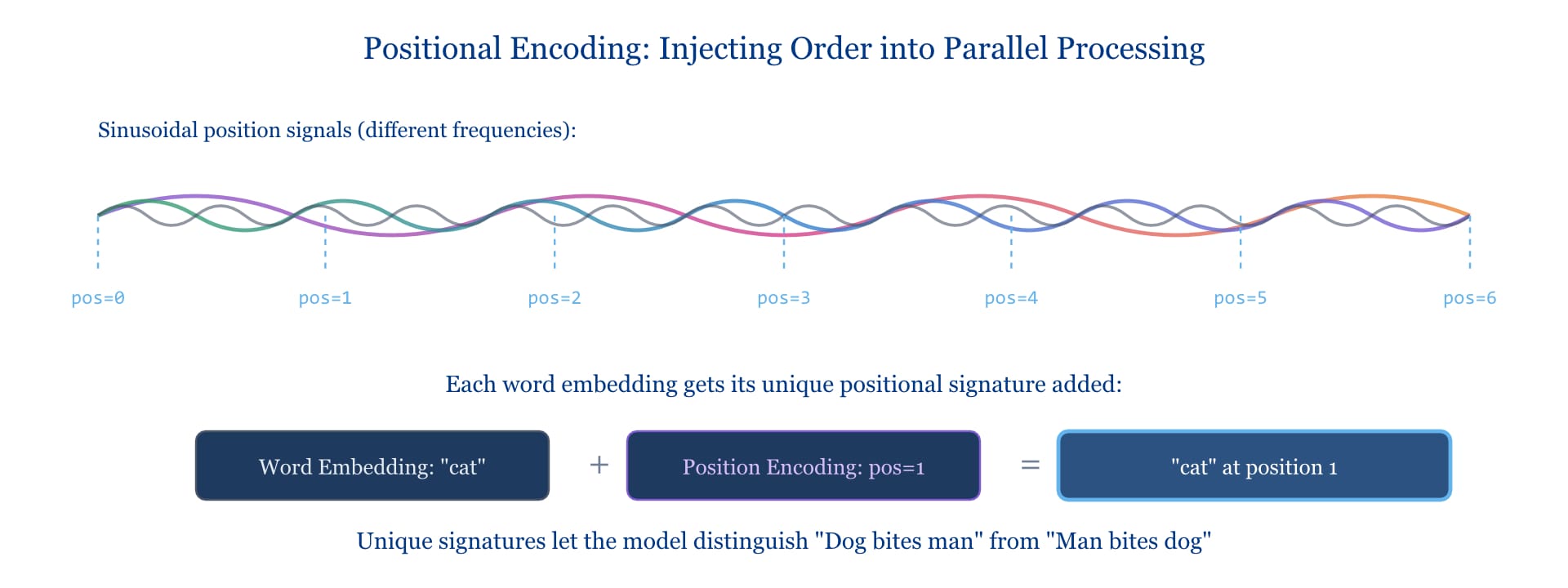
One puzzle: if we process everything simultaneously, how does the model know word order? "Dog bites man" and "Man bites dog" contain the same words but mean very different things.
The solution is positional encoding. Before processing, each word gets tagged with information about where it appears in the sequence. These positional signals get mixed into the word representations, allowing the model to reason about order even while processing in parallel.
Positional Encoding
The original Transformer paper used sinusoidal functions to generate these positions—waves of different frequencies that create unique signatures for each position. Later models experimented with learned positions, relative positions, and other schemes. But the core idea persists: inject order information explicitly, then let attention figure out which positional relationships matter.
From Transformers to Everything Else
The 2017 paper focused on machine translation—converting text from one language to another. But researchers quickly realized that the architecture was far more general.
In 2018, Google introduced BERT (Bidirectional Encoder Representations from Transformers), which learned to understand language by predicting masked words in sentences. BERT could be fine-tuned for almost any language task—question answering, sentiment analysis, named entity recognition.
From Transformers to Everything Else
That same year, OpenAI released GPT (Generative Pre-trained Transformer), which learned to predict the next word in a sequence. This simple objective, scaled massively, produced increasingly capable language generators. GPT-2 wrote coherent paragraphs. GPT-3 wrote essays. GPT-4 passed professional exams.
Vision Transformers showed that images, cut into patches and treated as sequences, could be processed the same way. Audio, video, protein structures, computer code—researchers found that almost anything could be tokenized and fed through attention layers.
The Transformer became the universal architecture.
What the Layman Should Remember
Here's the essence:
Before Transformers: Neural networks read language one word at a time, sequentially, like a tape recorder. Long-range relationships were hard to learn. Training was slow because computations couldn't be parallelized.
After Transformers: Neural networks see the entire input simultaneously. Every element can attend to every other element, computing relevance scores that capture meaning through relationships. Training is massively parallel.
The key insight: Meaning emerges from relationships. Attention is a mechanism for computing which relationships matter most. By doing this everywhere, for everything, all at once, Transformers capture the contextual nature of language in ways previous architectures couldn't.
The Philosophical Footnote
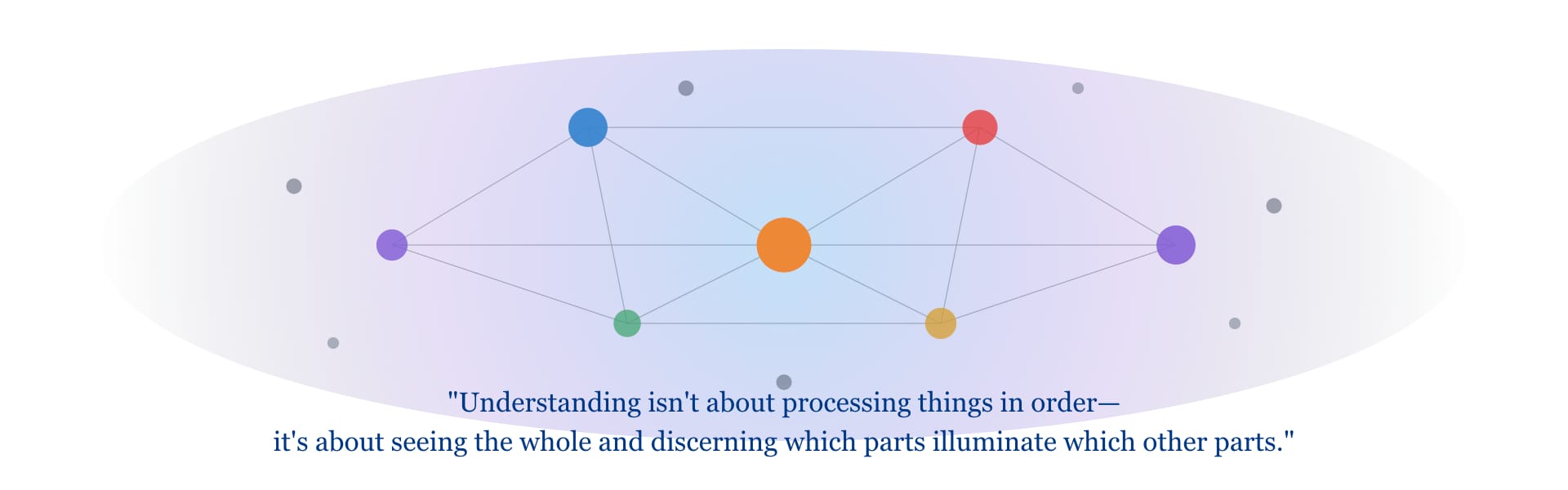
There's something almost meditative about the Transformer's worldview. It suggests that understanding isn't about processing things in order—it's about seeing the whole and discerning which parts illuminate which other parts.
The Whole is Greater Than Its Parts
This echoes ideas far older than neural networks. Hermeneutics—the philosophy of interpretation—has long emphasized the "hermeneutic circle": you understand the parts through the whole and the whole through the parts, in a perpetual loop. Gestalt psychology taught that perception is holistic before it's analytical.
Perhaps it's not surprising that this architecture has proven so powerful. It aligns with something deep about how meaning actually works—not as a linear accumulation of facts, but as a web of interconnected relationships, all grasped together.
Everything, everywhere, all at once.
But here's the thing about revolutions: they tend to reveal their own limitations. The Transformer's parallel attention is powerful, but it comes with costs—quadratic memory scaling, context window constraints, and an architecture that may be fundamentally misaligned with how reasoning actually works.
In my next article, "Attention Is Not All We Need," we'll explore what happens when everything everywhere all at once isn't quite enough—and what comes next.