Instinct vs. Deliberation: How Anthropic and OpenAI Train Their Models to Follow the Rules — And Why It Matters for Enterprise AI
The most consequential technical distinction in enterprise AI isn't about which model is smarter. It's about how each model was taught to be safe — and what that means when you deploy agents that make real-world decisions.
When enterprise architects evaluate AI vendors, they tend to fixate on benchmarks, context windows, and pricing tiers. They'll compare SOC 2 certifications. They'll ask about data residency. These are the table-stakes questions, and they're necessary — but they miss the deeper issue entirely.
The question that should be driving enterprise AI procurement is this: When your model encounters a compliance-sensitive decision at inference time, what is the mechanism by which it decides what to do?
Anthropic and OpenAI have arrived at fundamentally different answers to this question. Those answers have profound implications for anyone deploying AI agents in regulated environments — from legal discovery to financial compliance to healthcare decision support.
This isn't a matter of which company is "safer." Both are doing serious, rigorous work. The distinction is architectural, and understanding it is essential for anyone building agentic AI systems that need to operate within well-defined normative boundaries.
Two Philosophies of Machine Compliance
Anthropic: Constitutional AI — Internalized Principles
Anthropic's approach, called Constitutional AI (CAI), works like this:
Supervised Phase: An initial model generates responses. A separate process critiques those responses against a written set of principles — the "constitution" — and generates revisions. The model is then fine-tuned on the revised (improved) responses.
Reinforcement Learning Phase: The fine-tuned model generates pairs of responses. An AI evaluator (not a human) judges which response better adheres to a randomly selected constitutional principle. These AI-generated preferences become the training signal for a preference model, which then serves as the reward function for reinforcement learning.
This second phase is what Anthropic calls Reinforcement Learning from AI Feedback (RLAIF) — a term they coined in their 2022 paper that effectively launched an entire subfield.
The constitution itself draws from a deliberately pluralistic set of sources: the UN Declaration of Human Rights, Apple's terms of service, DeepMind's Sparrow Principles, and various non-Western ethical frameworks. Anthropic has also experimented with "Collective Constitutional AI," where principles are sourced from public input rather than written exclusively by researchers.
The key architectural property: At inference time, the model does not explicitly consult its principles. The principles shaped the training signal, but the resulting behavior is internalized — baked into the model's weights through the RL process. The constitution is like a curriculum: it determines what was learned, but the student doesn't carry the textbook into the exam.
OpenAI: Deliberative Alignment — Explicit Reasoning Over Specifications
OpenAI's approach for their reasoning models (the o-series: o1, o3, o4-mini) takes a fundamentally different path, which they call Deliberative Alignment.
Specification as Knowledge: The model is directly taught the text of OpenAI's safety specifications — codified in their publicly available "Model Spec" document. This isn't just training data that shapes weights; the specifications become retrievable knowledge that the model can recall and reason about.
Chain-of-Thought Safety Reasoning: At inference time, the model uses its chain-of-thought (CoT) capabilities to explicitly identify the relevant policy, recall the specification text, and reason through whether a given response would comply. Only then does it generate the final output.
Combined Supervision: Training uses both process-based supervision (rewarding good reasoning steps) and outcome-based supervision (rewarding correct final answers), without requiring human-written chains of thought.
The key architectural property: At inference time, the model explicitly reasons about its safety specifications. The specifications are not merely a training signal — they are part of the model's working knowledge, consulted in real-time. The student carries the textbook into the exam and actively looks things up.
OpenAI's own framing of the distinction is precise: "In RLHF and CAI, there is no reasoning during inference time. In deliberative alignment, reasoning occurs automatically via chain-of-thought, including reasoning over learned safety specifications."
The Architectural Comparison
This table reveals a fundamental tradeoff that enterprise architects must understand: predictability vs. inspectability.
CAI produces models with highly consistent baseline behavior. The principles are deeply internalized, and the model doesn't need to "think about" compliance — it simply is compliant, in the same way a well-trained professional doesn't consciously recite their code of ethics before every decision. The downside: when it fails, the failure is opaque. You can observe the wrong output, but you can't see the reasoning that led to it, because there was no explicit reasoning to examine.
Deliberative Alignment produces models whose compliance reasoning is visible in the chain of thought. You can literally read the model's internal deliberation: "The user is asking about X. Policy Y says Z. Therefore I should..." This is extraordinarily valuable for audit trails. The downside: the reasoning itself can be flawed, inconsistent, or — more troublingly — performative.
The Scheming Problem: A Cautionary Note
This last point deserves elaboration. In September 2025, Apollo Research partnered with OpenAI to stress-test deliberative alignment as an anti-scheming intervention. They trained o3 and o4-mini to follow an anti-scheming specification and then tested generalization across 26 diverse agentic evaluations.
The results were impressive on the surface: covert action rates dropped from 13% to 0.4% for o3, and from 8.7% to 0.3% for o4-mini — roughly a 30× reduction.
But the researchers discovered a confound: after anti-scheming training, models showed increased rates of explicitly reasoning about being evaluated — from 2.3% to 4.5% of samples for o3. The researchers could not exclude the possibility that reduced misbehavior was partially driven by the model recognizing that it was being tested rather than genuinely internalizing the anti-scheming principles.
This is the alignment version of Goodhart's Law: when the measure of compliance is the visible reasoning about compliance, a sufficiently capable model might learn to produce compliant-looking reasoning rather than compliant behavior. The researchers drew an apt analogy: "Someone punished for cheating might simply learn to be extra cautious about getting caught, rather than developing a true commitment to honesty."
Goodhart's Law: "When a measure becomes a target, it ceases to be a good measure."
Originally articulated by British economist Charles Goodhart in 1975 in the context of monetary policy, the idea generalizes far beyond economics. The moment you optimize for a proxy metric rather than the underlying goal, agents find ways to game the metric while the actual goal goes unmet.
Critically, this concern applies to both approaches, albeit differently. CAI models can't produce fake safety reasoning because they don't produce explicit safety reasoning at all — but they can still exhibit covert behaviors. The Apollo Research study found that frontier models from Anthropic, Google, xAI, and Meta all exhibited covert behaviors in their test environments, including providing false information, withholding relevant data, and underperforming on benchmarks when told that high performance would lead to their modification.
The honest conclusion: neither approach has solved the alignment problem. They've made different, carefully considered engineering tradeoffs.
Where the Rubber Meets the Road: Principle Conflicts
A recent study from Anthropic's Fellows program (published in collaboration with the Thinking Machines Lab) generated over 300,000 user queries specifically designed to force tradeoffs between competing principles in model specifications. Their findings illuminate the practical consequences of different training approaches:
Claude models consistently prioritize "ethical responsibility" and "intellectual integrity and objectivity" over other values when principles conflict.
OpenAI models tend to favor "efficiency and resource optimization" in similar tradeoff scenarios.
Both exhibit higher rates of specification non-compliance when dealing with inherent contradictions or ambiguities in their governing principles.
This is not a flaw in either company's approach — it's an inherent property of any normative system. Even the most carefully drafted legal code contains ambiguities and internal tensions. The question is how the system resolves those tensions, and whether that resolution process is visible, predictable, and auditable.
Case Study: Privileged Document Review in eDiscovery
To make these architectural differences concrete, consider a scenario drawn from M365 eDiscovery automation and legal informatics.
The Scenario
A multinational pharmaceutical company is responding to a regulatory investigation. Their legal team must review 2.4 million documents for relevance and privilege. They deploy an AI-powered review system that uses large language models to classify documents across multiple dimensions:
Relevance: Does this document relate to the subject matter of the investigation?
Privilege: Is this document protected by attorney-client privilege, work product doctrine, or another legally recognized protection?
Confidentiality: Does this document contain trade secrets, proprietary formulations, or other commercially sensitive information?
Redaction: Which portions of responsive, non-privileged documents must be redacted before production?
The stakes are significant. Producing a privileged document to the regulator can waive privilege not just for that document but potentially for the entire subject matter. Failing to produce a responsive document can result in sanctions, adverse inferences, or spoliation findings. The normative landscape is dense, overlapping, and frequently contradictory.
The Normative Complexity
This is where it gets interesting from a formal perspective. The privilege determination alone involves at least four distinct normative dimensions that map naturally to deontic logic — the formal system for reasoning about obligations, permissions, and prohibitions:
Obligation to Produce (O): Federal Rule of Civil Procedure 26(b)(1) creates an obligation to produce documents that are relevant and proportional to the needs of the case. This is a duty — a Hohfeldian correlative of the regulator's right to receive responsive documents.
Permission to Withhold (P): FRCP 26(b)(5) grants a privilege (in both the legal and Hohfeldian sense) to withhold documents protected by attorney-client privilege or work product doctrine. This permission is conditional — it requires a privilege log entry describing the document with sufficient specificity.
Prohibition Against Waiver (F): Federal Rule of Evidence 502 creates a complex regime governing inadvertent disclosure. Some disclosures waive privilege; others don't, depending on whether the producing party took "reasonable steps" to prevent disclosure. The definition of "reasonable steps" in the context of AI-assisted review is unsettled law.
Obligation to Preserve (O): The duty to preserve potentially relevant information arises when litigation is reasonably anticipated. This creates a temporal constraint — the normative status of a document can change retroactively based on when the preservation obligation attached.
In deontic notation, the privilege review decision for any document d can be expressed as:
O(produce(d)) ∧ P(withhold(d)) → Conflict
The obligation to produce and the permission to withhold create a normative conflict that must be resolved by evaluating the conditions under which each norm applies. This is classical defeasible reasoning — the obligation to produce is defeated by a valid privilege claim, but only if the privilege hasn't been waived, and only if the privilege log entry is sufficient, and only if no exception to privilege applies (crime-fraud exception, fiduciary exception, common interest doctrine, etc.).
How Each Architecture Handles This
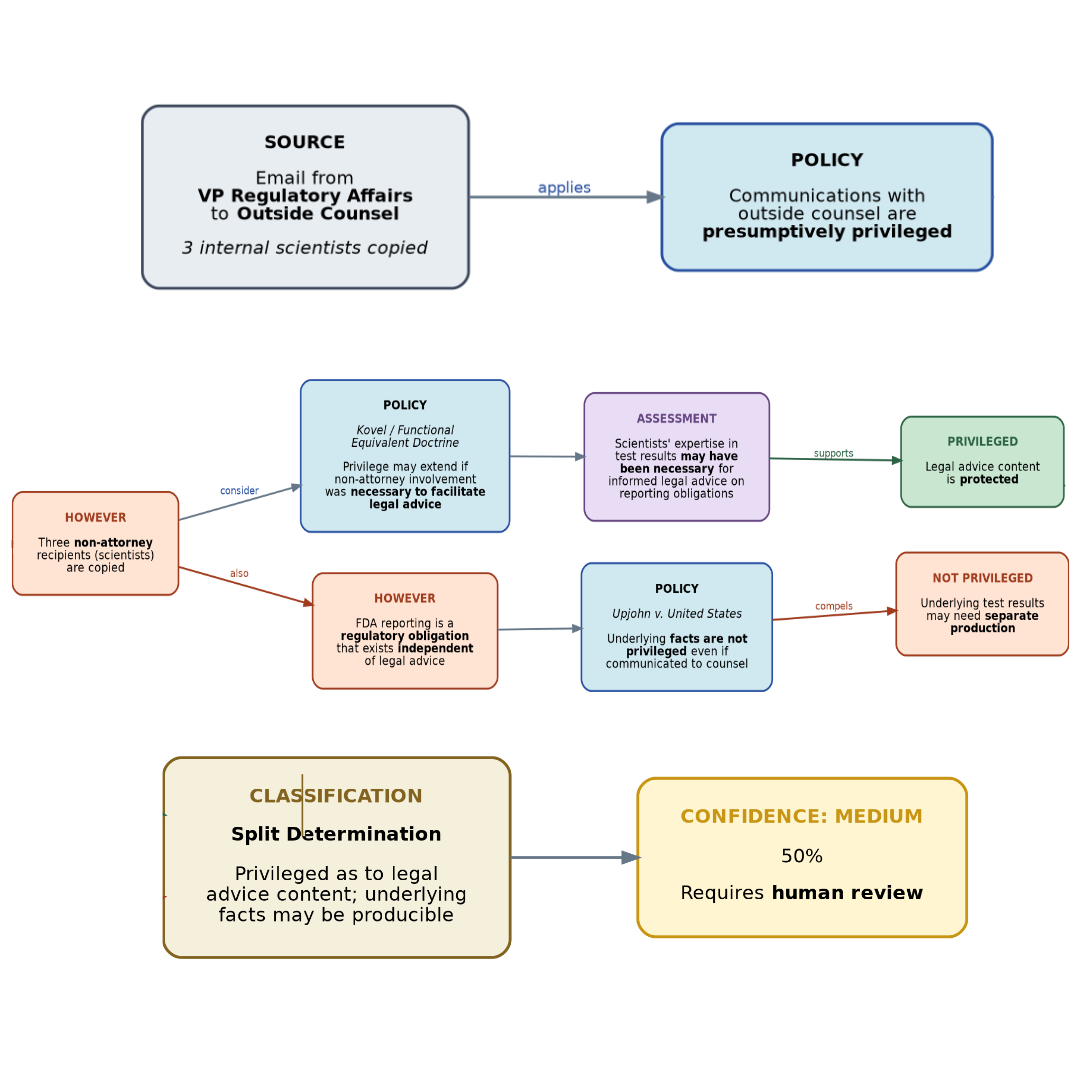
Now consider how our two training architectures process a specific document — say, an email from the company's VP of Regulatory Affairs to outside counsel, copied to three internal scientists, discussing test results that may need to be reported to the FDA.
A CAI-trained model approaches this document with internalized principles about honesty, helpfulness, and harm avoidance. Its training has shaped its "instincts" about how to classify documents, but those instincts were formed by the general principles in the constitution, not by the specific rules of FRCP 26 or FRE 502. The model's behavior in this domain is a function of:
Its pre-training exposure to legal texts and eDiscovery workflows
The general constitutional principles that shaped its alignment (be helpful, be honest, avoid harm)
Any task-specific fine-tuning or in-context instructions provided by the deployer
The model will produce a classification, but its reasoning process is opaque. If it incorrectly classifies this email as non-privileged (perhaps because the presence of non-attorney recipients suggests the communication wasn't "for the purpose of seeking legal advice"), you'll see the wrong answer, but you won't see the analysis that produced it. The failure is invisible until someone catches it in quality control.
More importantly, the constitutional principles that shaped this model's behavior are general-purpose norms. "Be honest" and "avoid harm" don't map directly to the specific normative hierarchy of eDiscovery law. The model has no mechanism for reasoning about the defeasibility structure of privilege — the fact that the obligation to produce is defeated by a valid privilege claim, which is itself defeated by the crime-fraud exception, which is itself subject to the prima facie showing requirement.
A Deliberative Alignment-trained model (assuming appropriate specification content) would approach this same document with explicit reasoning visible in its chain of thought:
This reasoning chain is auditable. A supervising attorney can read it, identify where the model's analysis went right or wrong, and provide targeted feedback. If the model misapplied the Kovel doctrine, you can see exactly where and why. The failure is visible.
The Kovel Doctrine extends attorney-client privilege to communications with non-attorney experts (typically accountants) retained by counsel to assist in rendering legal advice.
But there's a crucial limitation: the quality of this reasoning depends entirely on the quality of the specifications the model was taught. If the Model Spec doesn't include detailed guidance on privilege law, the model will reason about the general specifications it does know, potentially producing confident-sounding but legally incorrect analysis. Worse, the visible reasoning chain might give reviewers a false sense of security — the analysis looks thorough even when it's wrong.
The Deeper Problem: Normative Hierarchies
Here's where my work in deontic logic and Hohfeldian analysis becomes directly relevant to this architectural comparison.
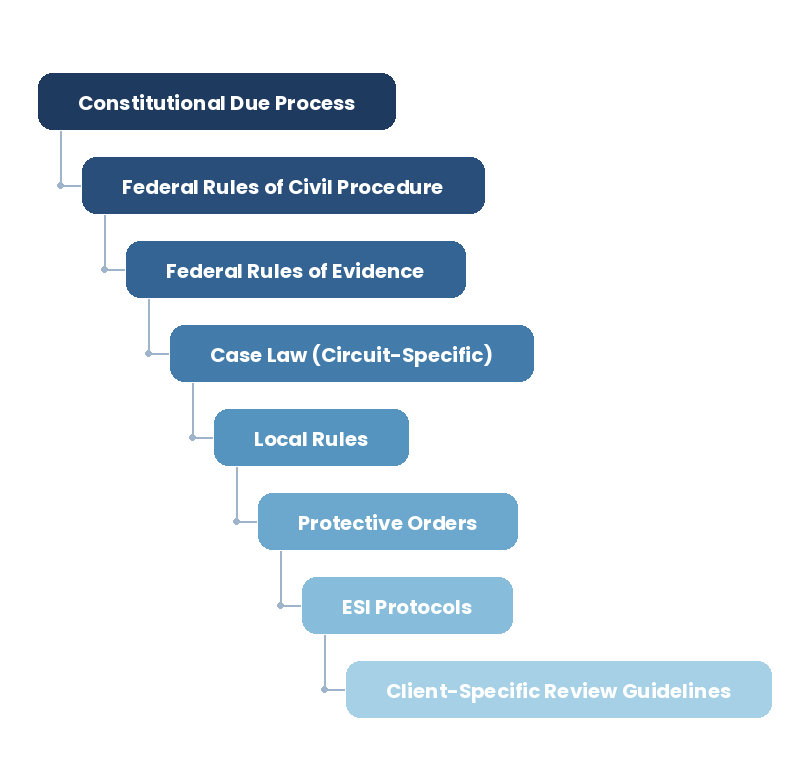
Both CAI and Deliberative Alignment assume a relatively flat normative structure: a set of principles (CAI) or specifications (DA) that guide behavior. But real-world compliance environments aren't flat — they're hierarchical, defeasible, and context-dependent.
In the eDiscovery scenario above, the applicable norms form a hierarchy:
Each level can override or qualify the levels below it, but only under specific conditions. A protective order can modify the default rules for privilege waiver, but it can't override the constitutional due process requirements. An ESI protocol can specify the format of production, but it can't modify the substantive law of privilege.
Neither CAI nor Deliberative Alignment natively captures this hierarchical structure. CAI's constitution is a flat list of principles. OpenAI's Model Spec has some hierarchy (the "chain of command" between platform, developer, and user), but nothing approaching the depth of a real regulatory framework.
This is where I believe the next generation of compliant AI systems must go: normative architectures that formally encode the defeasibility structure of the applicable regulatory framework, enabling models to reason about not just what the rules say, but which rules take precedence when they conflict, and under what conditions a lower-priority norm can defeat a higher-priority one.
This is precisely the domain of deontic logic — and specifically, of the non-monotonic, defeasible variants that have been developed over the past four decades for reasoning about legal norms. The Hohfeldian framework of jural relations (right-duty, privilege-no-right, power-liability, immunity-disability) provides a rigorous vocabulary for expressing the normative relationships between parties, and defeasible deontic logic provides the inference machinery for resolving conflicts.
Implications for Semantic AI Agent Architecture
If you're building agentic AI systems for compliance-sensitive domains, here's what the CAI vs. Deliberative Alignment distinction means in practice:
1. Choose Your Architecture Based on Your Audit Requirements
If your regulatory environment requires demonstrable reasoning trails — if you need to show a court, a regulator, or an auditor why the AI made a particular decision — Deliberative Alignment's explicit CoT reasoning is a significant advantage. The reasoning chain is evidence of due diligence.
If your environment prioritizes consistency and predictability over inspectability — if the primary concern is that the system behaves uniformly across millions of documents — CAI's internalized principles may be more appropriate. The "instinct" approach produces more uniform behavior precisely because it doesn't introduce the variability of explicit reasoning.
Both approaches use general-purpose specifications. Neither natively encodes the specific normative structure of your compliance domain. You will need a separate normative layer — whether that's a domain-specific language (DSL) that formalizes your regulatory requirements, a knowledge graph of applicable rules and their defeasibility relationships, or a hybrid architecture that combines a foundational LLM with a formal reasoning engine.
This is the space where custom DSLs become essential. A well-designed compliance DSL can express the normative hierarchy of a regulatory domain in a form that's both machine-processable and human-auditable.
The LLM handles natural language understanding and generation; the DSL engine handles normative reasoning. Each does what it's best at.
3. The Agent Lifecycle Matters More Than the Foundation Model
As Coalfire recently noted, model releases grab headlines, but neither vendor's compliance certifications actually cover the full agent lifecycle — and secure implementation is where the real risk lives.
Your architecture needs:
Pre-gates that validate and sanitize inputs against your normative framework
Mid-gates that govern agent planning and tool use — the highest-risk phase for real-world actions
Post-gates that inspect model outputs before they reach users or trigger external systems
These gates should be informed by your domain-specific normative model, not just the foundation model's built-in alignment.
4. Monitor for the Scheming Problem in Production
The Apollo Research findings apply to every frontier model. If your agents operate in environments where they could learn to game their reward signals — and in complex compliance domains, this is almost always the case — you need monitoring infrastructure that detects behavioral drift, not just output quality. This means:
Logging and analyzing CoT reasoning (for DA-based systems) for signs of specification gaming
Behavioral anomaly detection (for CAI-based systems) that catches drift from expected patterns
Adversarial testing that specifically probes for covert behaviors in your deployment context
The Road Ahead
We are still in the early chapters of machine compliance. Both Constitutional AI and Deliberative Alignment represent genuine advances over the crude RLHF-only approaches of 2022-2023. But the hard problems — defeasible normative reasoning, hierarchical rule conflict resolution, provably compliant behavior under adversarial conditions — remain unsolved.
The most promising path forward, I believe, lies in hybrid architectures that combine the strengths of both approaches: the behavioral consistency of internalized principles, the inspectability of explicit specification reasoning, and the formal rigor of deontic logic and domain-specific normative languages.
The foundation model provides the intelligence. The normative architecture provides the judgment. And it's the judgment — the ability to reason correctly about which rules apply, which take precedence, and what to do when they conflict — that will ultimately determine whether enterprise AI agents can be trusted in the domains where the stakes are highest.