The Context Trap: How Claude Code's Session Memory Can Narrow Your Solution Space
The longer and more technically dense a coding session becomes, the more the model's attention and generative probability distributions get pulled toward patterns, idioms, and architectural choices already present in that context.
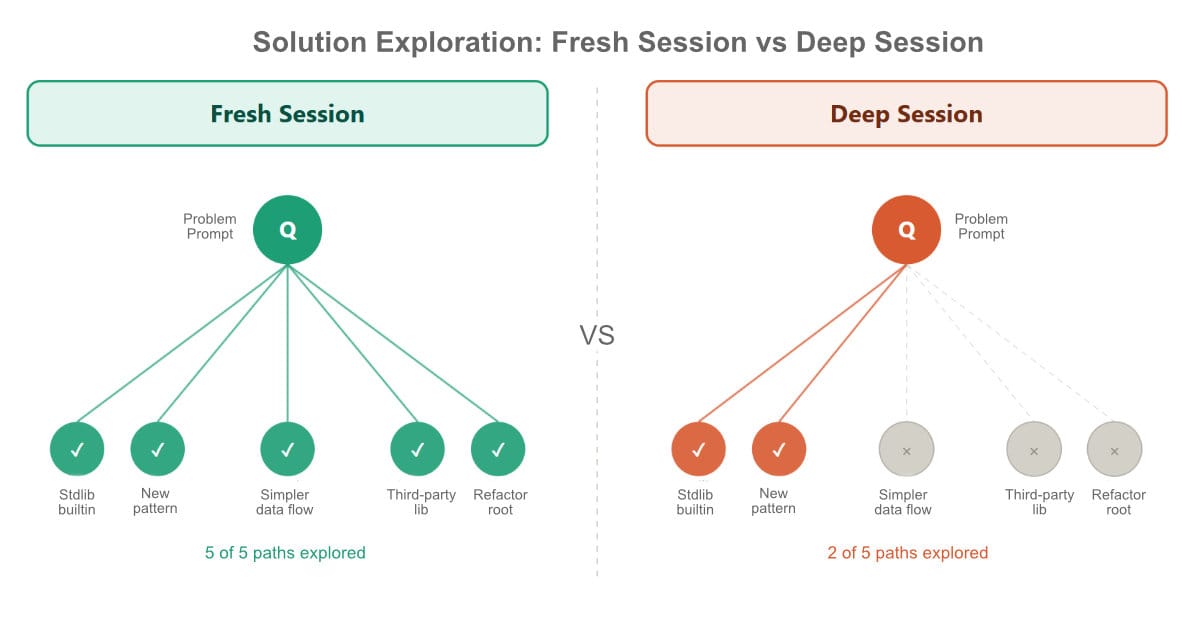
There's a phenomenon seasoned developers are starting to notice when working with Claude Code: the same prompt, sent to the same model, can produce dramatically different results depending on whether it arrives in the middle of an active coding session or in a fresh, context-free conversation.
The fresh session wins. Often by a wide margin.
The solutions surfaced in a cold-start conversation tend to be simpler, more architecturally coherent, and less entangled with the accumulated decisions of the surrounding session. The in-session response, by contrast, tends to be more constrained — anchored to patterns already established, blind to alternatives that would have been obvious from the outside.
This isn't a bug. It's a structural property of how large language models work in extended agentic sessions. But understanding it — and working around it — can dramatically improve your outcomes with tools like Claude Code.
What is Context Bias?
Context bias, as I'm using the term here, refers to the systematic narrowing of a model's solution space caused by the accumulated prior context of a session. The longer and more technically dense a coding session becomes, the more the model's attention and generative probability distributions get pulled toward patterns, idioms, and architectural choices already present in that context.
Think of it as cognitive anchoring — but for language models.
In human cognition, anchoring is the tendency to rely too heavily on the first piece of information encountered when making decisions. In an LLM session, something analogous happens, except the "anchor" isn't just the first input — it's the entire accretion of prior exchanges, file contents, error messages, partial solutions, and refactoring attempts that now fill the context window.
The model doesn't "forget" this material. It can't. Every token in the context exerts statistical pressure on what comes next. When you ask a model in the middle of a 50,000-token coding session "what's the best way to handle X?", it isn't answering that question in the abstract. It's answering it in light of everything that came before — which may include a great deal of prior art that subtly rules out the simplest answer.
The Mechanism: How Accumulated Context Constrains Generation
To understand why this happens, it helps to think about what a large language model is actually doing when it generates a response.
At every step, the model predicts the most contextually appropriate next token given everything that preceded it. "Contextually appropriate" means: consistent with the patterns, terminology, architecture, and problem framing already present in the conversation.
This is exactly what you want most of the time. It's what gives Claude Code its coherence — the ability to remember that you're using TypeScript, that you've adopted a particular DI framework, that error handling follows a specific convention. These constraints are useful. They prevent the model from randomly introducing Python idioms into your Node project.
But the same mechanism that produces coherent, session-aware code also produces something less desirable: path dependency. The model becomes progressively more committed to the architectural path already established, even when that path is suboptimal. New problems get solved within the existing framework rather than questioning whether the framework itself is the right approach.
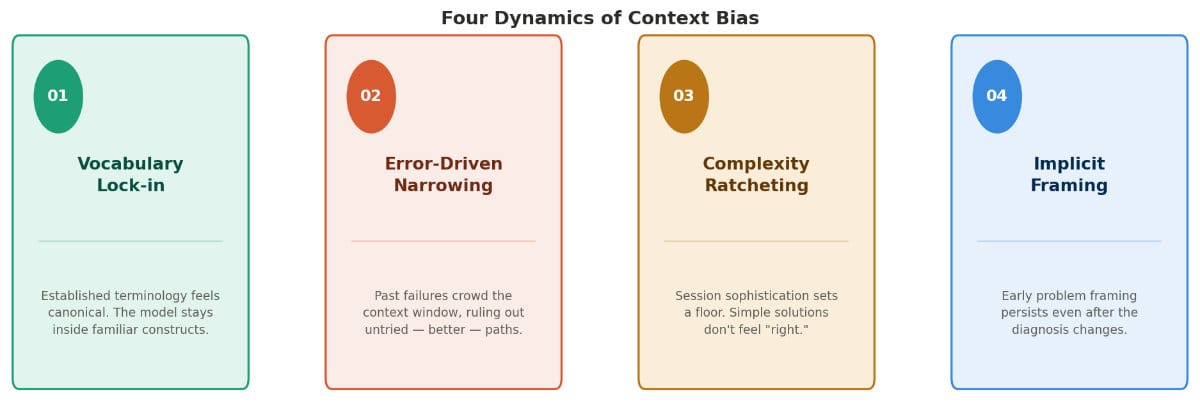
Several specific dynamics drive this:
Vocabulary lock-in. The terminology and abstraction layer used early in a session begins to feel "canonical" to the model. When you ask how to solve a problem, it naturally reaches for constructs that fit the established vocabulary — even when simpler primitives would serve better.
Error-driven narrowing. When a session includes failed attempts, compiler errors, and debugging cycles, those failures enter the context as negative examples. The model learns (within the session) what doesn't work — but this negative space can inadvertently crowd out approaches that were never attempted and would have worked well.
Complexity ratcheting. Sophisticated codebases generate sophisticated context. The model calibrates its response complexity to match the apparent sophistication of the session. A simple solution may never surface because it doesn't feel "right" for the level of abstraction established.
Implicit framing. Early problem framing shapes all subsequent reasoning. If the session established that "this is a distributed concurrency problem," the model will keep solving a distributed concurrency problem — even if the root cause turned out to be a simple configuration error.
Observable Patterns
Context bias tends to manifest in a few recognizable ways:
The refactoring spiral. You ask Claude Code to simplify some logic. It produces a simpler version — but one that still inherits the overall architecture of the current session. In a fresh session, it might have suggested a completely different data flow that made the local simplification unnecessary.
The framework assumption. Deep in a session that started with React, the model assumes React when answering questions about UI state — even if a simpler approach (vanilla DOM, Web Components) would be dramatically more appropriate for the specific subproblem you're now facing.
The fixation on recent errors. When a session includes a long debugging sequence, the model can become oddly fixated on the problem domain of those errors, even after they're resolved. It keeps proposing solutions that defend against that class of error rather than moving cleanly forward.
The missing abstraction. Perhaps the most subtle: the model fails to suggest a higher-order abstraction (a new pattern, a design principle, a standard library function) that would elegantly collapse several tangled pieces — because nothing in the session's context pointed toward it.
Strategies for Developers
Understanding context bias suggests several practical interventions. These range from simple session hygiene to more deliberate architectural prompting strategies.
1. The Cold-Start Validation Technique
When you've spent significant time on a problem in Claude Code and feel stuck or uncertain about the solution, deliberately take the core question to a fresh conversation with no context.
Strip the problem down to its essence: "Given X constraint, what's the cleanest approach to Y?" Omit the session history, the prior attempts, the specific codebase details. You want to see what the model reaches for before it's been conditioned by your session's accumulated choices.
If the fresh session suggests something dramatically different — especially something simpler — that's a signal worth taking seriously. It doesn't mean the session solution is wrong, but it means you should consciously evaluate both.
2. Strategic Context Reset
Claude Code's /clear command is more powerful than it appears. Don't think of it merely as freeing up context window space. Think of it as a cognitive reset that allows the model to approach subsequent questions without the statistical gravity of prior decisions.
A useful heuristic: when you transition from debugging to architecture (or vice versa), clear the context. These two modes of engagement benefit from very different orientive priors. Debugging wants rich context about what has been tried. Architecture wants clean slate reasoning about what should be.
3. Explicit Counter-Framing
When making a request in a mature session, explicitly instruct the model to consider alternatives outside the current approach:
"Setting aside the current implementation, what are three fundamentally different approaches to this problem? Include approaches that might require refactoring what we've already built."
This counter-framing instruction directly counteracts the model's natural tendency toward path-consistent solutions. It gives the model explicit permission — and a mandate — to search outside the established solution space.
4. The Rubber Duck Prompt
Use fresh-session Claude as a rubber duck for your session-Claude's solutions. Describe what Claude Code produced to the fresh conversation and ask: "What are the weaknesses of this approach? What simpler solution might achieve the same goals?"
This creates a productive adversarial dynamic between session and fresh contexts that can surface blind spots neither would catch alone.
5. Architect First, Then Code
Before any substantial coding session, have a dedicated architecture conversation in a separate, clean context. Use that conversation to establish the high-level approach, design patterns, and key abstractions — then bring those decisions into your Claude Code session as explicit constraints.
This inverts the natural order (code → implicit architecture) in favor of (explicit architecture → code), which significantly reduces the risk of context bias locking you into a suboptimal path early.
6. Named Checkpoints
Periodically during long sessions, ask Claude Code: "Summarize the architectural decisions we've made in this session and the reasoning behind each." Save that summary. If you need to start a fresh session, it becomes the compressed, intentional context you carry forward — rather than the entire sprawling history.
This is analogous to writing commit messages: you're forcing explicit articulation of decisions that would otherwise remain implicit.
7. Probe for Simpler Solutions Directly
Make it a regular practice in long sessions to ask:
"Is there a significantly simpler approach to this that I might not be seeing because of how this session has developed?"
This prompt exploits the model's self-awareness about context effects. It's remarkable how often it produces a genuine "actually, yes" response — surfacing an approach the model had available but hadn't offered because it didn't fit the session's established register.
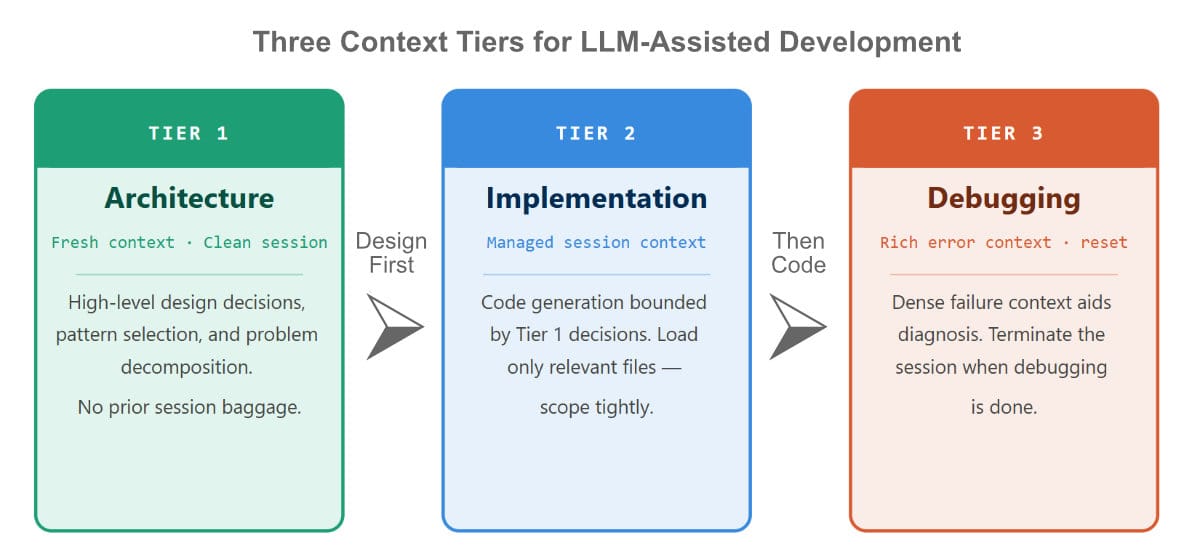
A Framework: Context Tiers for LLM-Assisted Development
Based on the context bias phenomenon, I find it useful to think about LLM-assisted development in terms of three context tiers, each appropriate for different phases of work:
Tier 1: Architecture (Fresh Context) High-level design decisions, pattern selection, technology evaluation, and problem decomposition. These conversations should happen in clean sessions with minimal prior context. The goal is broad solution-space exploration, not coherent implementation.
Tier 2: Implementation (Managed Session Context) Actual code generation, bounded by architectural decisions established in Tier 1. Context should be deliberately scoped — loaded with the specific files and constraints relevant to the current task, not the entire project history. Claude Code's @ file references help here.
Tier 3: Debugging (Rich Error Context) Active debugging sessions benefit from dense context about the failure — error messages, execution traces, recent changes. But these sessions should be terminated (not carried forward) when debugging transitions back to implementation or design.
The discipline of not letting these tiers bleed into each other — not bringing your debugging session's error-saturated context into an architecture conversation, not doing architectural rethinking inside an implementation session — goes a long way toward mitigating context bias.
The Deeper Implication
There's something philosophically interesting here that goes beyond tooling advice.
Context bias in LLMs is, in a sense, a mirror of how human expertise can become a liability. The experienced developer who has solved a class of problem many times may reach for a familiar hammer even when the problem is a screw. The junior developer, unburdened by ingrained patterns, sometimes asks the naive question that cracks the whole thing open.
When you use a fresh Claude session as a check on your Claude Code session, you're not just compensating for a technical limitation. You're institutionalizing the discipline of beginner's mind — the deliberate suspension of expertise's blinders in service of seeing what's actually there.
The best developers I've worked with over three decades have always had this capacity: the ability to step back from their own accumulated context and ask, with genuine openness, whether they're solving the right problem in the right way.
LLMs don't always make this easier. Long sessions can make it harder, by outsourcing and amplifying exactly the kind of path dependency that human expertise already tends toward.
But managed deliberately, the interplay between session context and fresh context — between depth and beginner's mind — is one of the most powerful patterns available in AI-assisted development.