The Phone Is Always Recording: Big Law's Ambient AI Problem and the Discipline of Cognition
How do we get an entire generation of associates to even notice they are doing something legally consequential?

– 8 min read
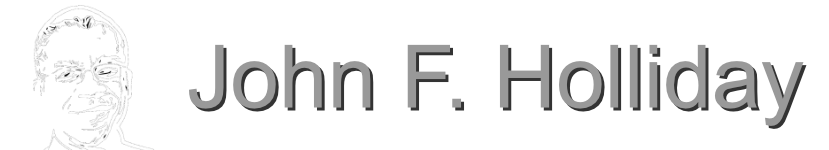
How do we get an entire generation of associates to even notice they are doing something legally consequential?

A friend who runs litigation risk and technology at one of the more storied firms in Manhattan called me last week with the kind of question lawyers don't usually ask out loud. Not "what's the latest AI tool?" — they get pitched on those daily — but something closer to: how do we get an entire generation of associates to even notice they are doing something legally consequential?
His example was almost banal. Junior associates routinely record client meetings on their phones. Not as some kind of evidentiary maneuver. They do it the way someone in 2010 might have jotted notes on a legal pad — automatically, without thought, because that is how they have processed information since high school. Press the button, get the transcript, search it later. The phone is just doing its job.
Except now the phone is also routing audio through an AI transcription service whose terms of service granted training rights three updates ago, the recording lives in a personal iCloud, the meeting itself was privileged across three jurisdictions with different consent-to-record statutes, and somewhere downstream a model has internalized client strategy as a statistical pattern. The associate sees a transcript. The firm has just generated a discovery-eligible artifact, a probable ethics violation, a regulatory exposure, and a privilege problem that no motion to compel has even imagined yet.
And — here is the part that should keep general counsel up at night — the associate is not a bad person. He is doing exactly what his tools were designed to make frictionless. The meeting just happened. He is being efficient.
This is the shape of the crisis. It is not about bad tools or careless lawyers. It is about a generation of practitioners whose ambient relationship with software has outrun their institutional capacity to recognize when an automatic action carries professional weight. And the institutions tasked with catching the gap — the in-house IT departments, the risk committees, the CLE programs — are themselves climbing a learning curve they cannot publicly admit exists.
Here is the uncomfortable fact my friend conveyed, slightly more diplomatically: the firm's own technology group, by every objective measure one of the most sophisticated in the AmLaw 10, does not have the depth on AI it would need to actually govern AI. That isn't a slight on the people. It's a structural observation.
Most firm IT departments were built to run Outlook and the DMS and Citrix without crashing. They were not built to evaluate whether a model's training data contaminates the firm's privileged corpus, or whether retrieval augmentation across matters violates the ethical wall that the firm spent a fortune erecting. These are not technology questions in the usual sense. They are hybrid questions — part computer science, part professional responsibility, part epistemology — and the people who can fluently operate across all three are roughly as common as bilingual deontic logicians.
So the firm hires a senior litigation risk advisor — exactly the role my friend now occupies — and that person spends most of his day reverse-engineering what associates have already done. By the time he is involved, the recording has been made, the transcript has been generated, the email summarizing the privileged conversation has been auto-composed by an assistant nobody approved. Governance, in the way most firms actually practice it, is forensic rather than preventive.
There is a temptation, especially among partners who came up before ubiquitous mobile computing, to read the associate's behavior as a discipline failure. Why didn't he think? The honest answer is that thinking is exactly what the technology is designed to make unnecessary. The phone has been recording his life since he was twelve. The cloud has been quietly taking custody of his data since high school. Free AI tools have absorbed his work since law school. Every one of these tools earned his trust by being useful, frictionless, and silent about what it was doing in the background.
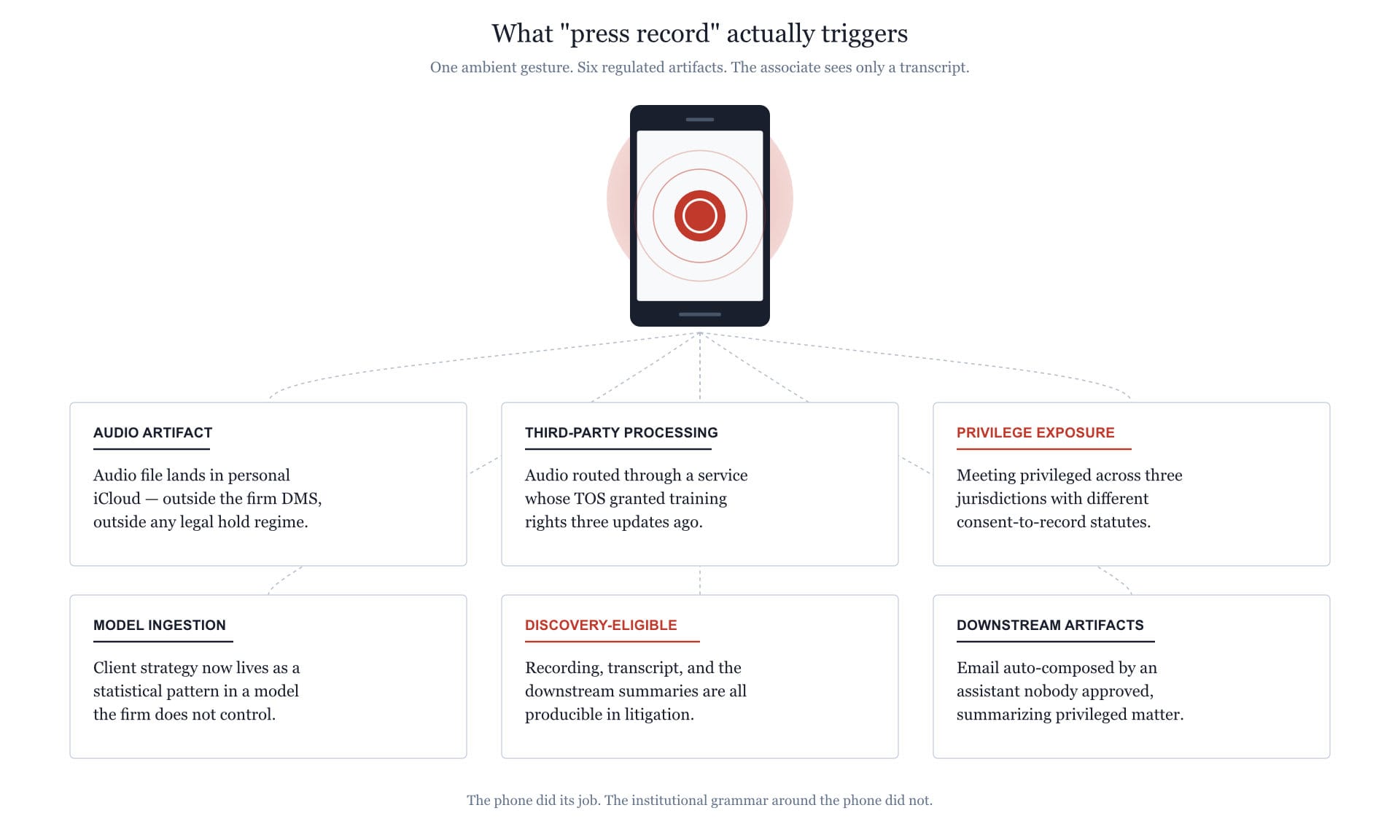
Compare this to how a surgical resident learns sterile technique. Sterile technique is also tedious, also frictional, and also makes no immediate sense to a fourteen-year-old. But residents internalize it because it is taught as a discipline of cognition rather than a list of rules. They are not memorizing a policy; they are being trained to see certain situations differently — to recognize when ordinary motions become consequential and when an automatic gesture becomes a violation. The discipline lives in the perception, not in the checklist.
That is the muscle that has not been built in young lawyers around technology. They have policies, plenty of them, drafted by very expensive lawyers and circulated as PDFs that nobody reads after onboarding. What they do not have is the trained perception that lets them notice — before they press record, before they paste the brief into the public chatbot, before they let the meeting assistant join the call — that something professionally weighty has just been activated. The policy gap is real, but the perception gap is the deeper problem.
It helps to step back and ask what the underlying problem actually is. It is not, I would argue, that the tools are insufficiently regulated. It is that meaning, permission, and obligation are not structurally encoded anywhere these tools can see.
One useful diagnostic frame here is the one Hohfeld gave us a century ago for legal relationships: rights and duties, privileges and no-rights, powers and liabilities, immunities and disabilities. Every act in legal practice can be analyzed through these jural correlatives, and lawyers — even young ones who have never read Hohfeld by name — already think this way about courtroom conduct. They know intuitively that filing a notice of appearance changes their power-liability relationship with the court. What they do not yet do is recognize that pressing record on a phone changes a privilege/no-right relationship between the firm and the rest of the world, or that uploading a draft to a model's context window can extinguish work-product immunity in a way no opposing counsel has yet thought to argue but eventually will.

A second frame, complementary, comes from deontic logic — the formal study of obligation, permission, and prohibition. Most AI products in the legal market operate under an implicit deontic regime in which everything not explicitly prohibited is permitted. This is the inverse of professional ethics, where everything not explicitly permitted by a rule, a privilege, or a client's informed consent is at minimum suspect. The mismatch is not a bug in the tools; it is a category error in how they have been integrated into practice.

A related observation worth making: large language models, as currently deployed, are epistemically promiscuous. They blend testimony, inference, retrieval, and fabrication into a single confident output and offer no native way to mark which is which. To a lawyer trained — even unconsciously — to track the provenance of every belief, this should feel as alien as a witness who refuses to distinguish what they saw from what they heard from what they assumed. The fact that it does not yet feel that alien to many young associates is the symptom this whole essay is about.
There is no clean technical fix sitting on a shelf. There is, increasingly, a body of work — call it Semantic AI, call it grammar-grounded agents, call it whatever — that takes the position that meaning, permission, and obligation are first-class structural concerns rather than guardrails bolted onto opaque systems. The diagnostic value of that work, even before any of it is deployed in a firm, is that it gives you a vocabulary for naming what is missing. The associate's phone is not failing. The institutional grammar around the phone is failing. That is a different problem with different remedies.
Imagine a junior associate who, before he presses record, registers — automatically, the way a surgical resident registers a non-sterile glove — that the meeting is privileged in two of the three jurisdictions involved, that the recording app's TOS was last updated in a way his firm's risk team never reviewed, and that the partner has not given verbal consent on the record to the form of memorialization. He does not run through a checklist. He perceives the situation as professionally loaded, the way one perceives a curb before stepping off it.
Imagine a partner who declines a free transcription service not because IT told him to, but because he has internalized that consideration in a contract you did not pay for is the data you provide, and the data in this case is his clients' strategy.
Imagine an associate using a generative tool to draft, who reflexively distinguishes — in his own working memory, not just in the document — what is testimony, what is inference, what is fabrication, and what is retrieved from where. Who treats the model's output as evidence of unknown provenance until he has independently verified it, the way he would treat an unsourced quotation in someone else's brief.
This is not Luddism. This is the discipline that has always characterized good lawyers, good auditors, good clinicians, good engineers. The tools change. The discipline does not. What is changing right now, and quickly, is the surface area over which the discipline has to operate, because every consumer device in the building is now a potential producer of regulated artifacts.
Three suggestions, none of them novel, all of them harder than they sound.
First, treat AI literacy as a CLE-grade competency rather than an IT training. The current onboarding model — a slideshow during the first week, a policy PDF, an annual refresher — is calibrated for software whose risk profile is bounded. AI is not that. The literacy required is closer to evidence law than to Excel, and it should be staffed accordingly.
Second, push to express governance in forms that are actually operational. PDFs nobody reads are not a governance regime; they are a liability shield. There is meaningful work being done on machine-readable policy and on agent architectures that can refuse actions on the basis of structured constraint rather than vibes. Even if the firm is not ready to deploy any of this, the exercise of writing the policy in a form a machine could enforce surfaces the ambiguities the prose version was hiding.
Third, give the senior risk advisors — the ones whose phone calls inspired essays like this one — actual authority over AI procurement and use, not advisory roles invoked after the contract is signed. The reason those people exist is that nobody else in the firm has the cross-domain literacy to spot the problems early. Treating them as consultants rather than gatekeepers is a structural decision to receive the bad news late.
The deepest irony in all of this is that law, of all professions, ought to be best equipped to handle it. We have spent centuries developing doctrine on what words mean in context, on the difference between the four corners of a document and the surrounding circumstances, on the evidentiary status of hearsay, on the precise conditions under which a privilege survives or is waived. The entire common-law tradition is a working theory of meaning under adversarial conditions. AI did not invent the problem of unreliable knowledge under time pressure; it merely scaled it.
The good news is that the discipline is teachable. The bad news is that nobody is currently teaching it, the institutions tasked with teaching it are themselves still learning, and every meeting recorded on every associate's phone in the meantime is generating artifacts the firm will be answering for in five to ten years.
A semantic frame on AI is one way to start naming what is missing. The naming itself is the precondition for any of the rest of it.







